
论文:Efficient Learned Spatial Index With Interpolation Function Based Learned Model
IEE 链接:https://ieeexplore.ieee.org/abstract/document/9816118
SPRIG之前的处理方法:
索引构建: SPRIG 系统包括三个组件:1)n × m 网格布局 Gn×m,其中 n 是沿 x 维度的列数,m 是沿 y 维度的行数;2)一个表 T;3)基于空间插值函数的学习模型 M。
构建 Gn×m 的主要思想是找到每个维度的边界值。这些边界值可以将空间划分为沿一个维度的多个列,并确保每个列具有几乎相等的数据记录数。定义 x 和 y 维度的边界为集合 Bx 和 By,其中 |Bx| = n + 1,|By| = m + 1。总共有 n × m 个网格单元,我们有 Gn×m = {Bx, By}。
接下来,采用简单的空间填充曲线对这些单元进行索引。首先,将整数分配在范围 [0, n × m – 1] 内作为沿 x 维度的单元 ID,并定义一个二维数组 Cid 来存储这些单元 ID:Cid[i][j] = j + n * i,其中 0 ≤ i < n 且 0 ≤ j < m。然后,可以建立一个表 T 将单元 ID 映射到覆盖记录,其中键是单元 ID,值是一个表示指向第一条记录的指针和单元中记录数的对(firstAddress, size)。基于 Gn×m 和 Cid,我们可以拟合空间插值函数 Cid * M(Bx, By) 作为我们的学习模型。
查询处理: 处理查询的原则是定位包含查询点的单元。然后,基于定位到的单元,可以采用范围查询和 kNN 查询策略来过滤和细化所需的数据点。具体而言,定位覆盖查询点的单元有两个步骤:
Step-1: 预测单元 ID(cell id) 给定查询点 (xq, yq),可以使用学习模型获得预测的单元 ID,即 pid = M(xq, yq)。然后,可以简单地计算 pid 在 Bx 和 By 集合中的位置。也就是说,lpx = pid mod n,lpy = pid // n。
Step-2: 用本地二进制搜索定位实际单元 ID 给定错误保证的一对值 (egx, egy),通过在 Bx 和 By 上进行本地二进制搜索,可以获得查询点的实际 x 和 y 位置,分别表示为 lrx 和 lry。在 Bx 集合上的搜索范围是 [lpx – egx, lpx + egx],而在 By 集合上是 [lpy – egy, lpy + egy]。最后,可以获得查询点 (xq, yq) 的实际单元 ID,即 rid = lry * n + lrx。
以 (38, 420) 为例,它应该位于单元 ID = 51 的单元中,即 rid = 51。假设预测的单元 ID pid = M(38, 420) = 44,且 (egx, egy) = (1, 2)。在 Step-1 中,lpx = pid mod n = 44 mod 8 = 4,lpy = pid // n = 44 // 8 = 5。在 Step-2 中,由于 egx = 1,Bx 上的二进制搜索范围是 [3, 5],而由于 egy = 2,By 上的搜索范围是 [3, 7]。由于 Bx[3] = 31 < 38 < Bx[4] = 42,我们得到 lrx = 3。类似地,由于 By[6] = 410 < 420 < By[7] = 500,我们可以得到 lry = 6。因此,rid = lry * n + lrx = 6 * 8 + 3 = 51。
获得查询点的实际单元 ID rid 后,可以从该单元开始执行范围查询和 kNN 策略,以收集查询结果。
SPRIG+是在SPRIG的基础上提出的多维学习型索引。SPRIG+的核心构建逻辑在于通过改进的IH-tree+模型来映射二维空间坐标到网格单元ID。在构造IH-tree+之前,根据数据分布,将二维空间划分为n×m的自适应网格,生成x和y维度的边界值集合Bx和By。
IH-tree+采用平衡的四叉树结构进行构造,首先从根节点开始,递归地将二维区域划分为四个子区域。接着每个内部节点记录其对应的中心点坐标(基于Bx和By的索引位置),并指向四个子节点。当达到预设树高h时停止划分。IH-tree+的叶子节点不再进行复杂的函数拟合,而是直接存储该子区域在 和 中的边界位置索引(四个整数值)。在构建叶子节点时,应用动态编码技术,将子区域内的单元ID重新进行局部编码,从而确保预测结果被严格限制在叶子节点覆盖的范围内。当查询点落在某个叶子节点代表的子区域时,首先根据该节点存储的边界位置计算局部网格的规格:
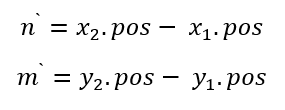
然后在局部区域内,四个角点的单元格位置值不再使用全局编码,而是进行本地化编码。四个角点的值定义如下:
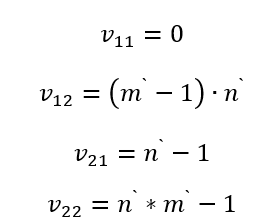
接着,利用归一化后的查询坐标计算局部预测位置:
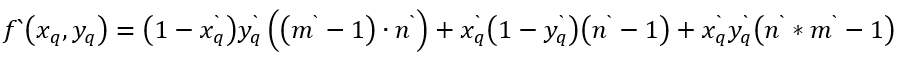
最后,得到局部预测ID后,通过坐标偏移将其还原为全局网格中的ID:
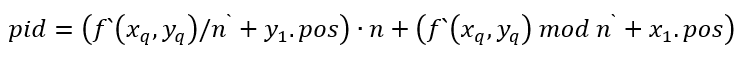
动态编码强制预测值落在叶子节点的覆盖范围内,控制误差在固定范围内,提高了查询的准确率。




